© 2026 IEEE. Personal use of the IEEE materials here is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of these works in other works.
Submitted Works

Abstract
Classical Hamilton–Jacobi safety verification breaks under high dimensions because grids explode combinatorially. We sidestep this by quasilinearizing viscous HJI equations through a generalized Cole–Hopf transform, reducing nonlinear safety propagation to Gaussian heat-kernel inference. The result is a scalable, plug-and-play safety wrapper for autonomous systems with provable concentration bounds and linear convergence — trading grid explosion for controllable Monte Carlo sampling.
Beyond Sampling: Kolmogorov PDE Regression for Robust Diffusion Policies
Abstract
Finite-dimensional (FD) diffusion policies are well-known to degrade in performance in long-horizon control prediction settings owing to temporal drift of the backward action trajectory and the spectral
artifacts associated with the finite grid discretization from which actions are sampled. This hinders
their reliable deployment when policies must satisfy all allocated and functional baselines with certifiable
robustness guarantees. To address this deficiency, we lift diffusion to an infinite-dimensional subset of a
Hilbert Space and transform the Monte-Carlo action sampling generation into a deterministic PDE regression.
This reparameterization (i) attenuates the instability associated with Monte Carlo rollouts in FD settings;
whilst (ii) enabling reconfigurability of the action space in spectral form to support the entire data manifold; and (iii) provides dimension-independent convergence guarantees. Specifically, we lift the backward Kolmogorov
score function to a Cameron-Martin space, introducing a physics-grounded Kolmogorov residual as a diagnostic during
learning. Our schemes are validated on contact-rich manipulation (\texttt{PushT}) and manufacturing constant
work-in-processes (\texttt{CONWIP}) flow forecasting. Across action (reverse) denoising steps on \texttt{PushT},
we notice an inter-step drift convergence accuracy of 98% on our infinite-dimensional formulation versus
85% on the FD visuomotor policy tasks. In addition, we achieved a 28.4% improvement in forecasting
accuracy over LSTM baselines and near-perfect recall in bottleneck event detection for manufacturing \texttt{CONWIP}.
To further imbue robustness into diffusion workflows, we integrate our approach with Hamilton–Jacobi reachability
safety analysis, so that our approach yields certified safe policies that reduce deadlocks by 96% in stochastic
factory automation discrete event systems.
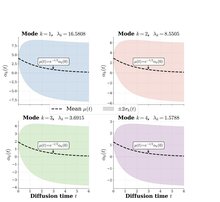
Infinite-Dimensional Visuomotor Diffusion Policies from SDE Parameterization
65th Conference on Decision and Control, Honolulu, Hawaii
Abstract
Diffusion policies are very consequential in learning the visuomotor policies of many autonomous systems. Despite the underlying diffusion process' existence in an infinite-dimensional (ID) function space, practical autonomous systems implementations discretize diffused control trajectories within finite-dimensional (FD) vector spaces. We set diffusion visuomotor policies in the natural ID fabric of the problems they attempt to solve, approximating controls ideally with all potential solutions within the function space, including their relative probabilities, while precisely deferring discretization as long as possible. We show that the Backward Kolmogorov Equation (BKE) in a Hilbert space turns stochastic diffusion score regression into deterministic PDE regression with a Cameron-Martin (CM) loss that achieves a dimension-independent total-variation bound on the underlying probability distribution.

A Fast Universal Collision-free Agentic Model: Compact Illusory Representation and Memory-Efficient Incremental Mapping
Science Robotics
Abstract
We present a universal collision-free planner for open-embodiment robots that combines compact implicit scene representations with memory-efficient incremental occupancy mapping. The method generalizes across robot morphologies without retraining and achieves real-time planning in cluttered, partially observed environments.
Accepted or Published Works

Abstract
We transform emergency room trauma resuscitation into a multi-agent control problem and propose a generalized Nash equilibrium-seeking policy that coordinates multiple clinical agents under resource constraints, improving patient outcomes while satisfying safety and fairness requirements.

Abstract
LevelSetPy is a Python package for numerically solving hyperbolic Hamilton-Jacobi PDEs that arise in reachability analysis and level set methods. Leveraging JAX-based GPU acceleration, it achieves order-of-magnitude speedups over the standard MATLAB toolbox while providing a modern, differentiable programming interface for robotics and control researchers.

Abstract
Supplementary material accompanying LevelSetPy, providing extended benchmark evaluations, numerical examples, and performance comparisons against MATLAB toolbox baselines on Hamilton-Jacobi reachability problems in up to six dimensions.

Abstract
We present a singularly-perturbed backstepping controller for whole-body strain regulation in multi-section continuum robots modeled by discrete Cosserat rods. The composite fast-slow design decouples the bending and shear strain dynamics, achieving convergence guarantees and superior transient performance compared to monolithic control laws.

Abstract
This paper introduces LevelSetPy, a Python-native reimplementation of the Hamilton-Jacobi reachability toolbox with GPU support via JAX. We demonstrate its correctness and efficiency on canonical pursuit-evasion games and high-dimensional reachability problems relevant to autonomous systems.

Abstract
We analyze the structural (controllability, observability, and passivity) properties of multi-section soft robots modeled by discrete Cosserat rod theory. Exploiting these properties, we design an energy-based controller with provable stability guarantees and validate it in simulation on a three-section planar manipulator.
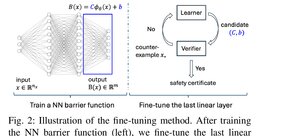
Abstract
We propose a counterexample-guided training procedure for neural network barrier functions that incorporates a formal verifier in the training loop. The algorithm terminates with a certificate of correctness and significantly reduces the barrier function training time compared to purely adversarial approaches.

Abstract
PCLAST learns a continuous latent state space from high-dimensional observations in which planning with simple interpolation is provably correct. By optimizing for topological planability rather than reconstruction fidelity, the learned representations support reliable goal-conditioned planning in complex visual environments without environment-specific reward engineering.

Abstract
We formulate and solve a continuous-time mixed H2/H-infinity reinforcement learning problem for output-feedback control synthesis without a known system model. The algorithm iterates policy evaluation and improvement steps on data collected from the system, converging to an optimal robust policy under disturbance attenuation constraints.

Abstract
We study robust policy optimization in continuous-time stochastic systems under the mixed H2/H-infinity performance criterion. Combining stochastic differential equation theory with modern policy gradient methods, we derive convergence rates and demonstrate improved robustness to model uncertainty in uncertain dynamical systems arising in robotics and medical automation.
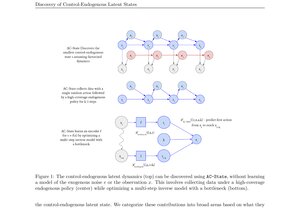
Abstract
We prove that multi-step inverse dynamics models recover controllable latent state representations with provable guarantees under a rich-observation MDP assumption. The theoretical analysis resolves an open question on when self-supervised representation learning methods succeed for downstream control tasks.

Abstract
We extend interaction-grounded learning (IGL) to settings where actions affect the feedback signal itself. By incorporating action-inclusive feedback into the IGL framework, we derive provably efficient algorithms for learning reward-free representations and policies in partially observable environments, with applications to healthcare decision support.

Abstract
We present the mechanical design, kinematic modeling, and experimental validation of a soft pneumatic robot that immobilizes a patient's head during frameless MRI-guided radiation therapy. The mechanism compensates for involuntary motion in real time using a vision-based feedback loop, reducing positioning error to sub-millimeter accuracy.

Abstract
We present a convolutional neural network that predicts near-optimal beam orientations for IMRT prostate cancer treatment plans in under one second, matching the quality of column-generation-based optimization while reducing planning time by two orders of magnitude.


Abstract
This dissertation develops a multi-degree-of-freedom soft robotic system for real-time patient positioning and beam orientation selection in intensity-modulated radiation therapy (IMRT). Contributions include continuum robot modeling via Cosserat rod theory, neuro-adaptive control for 6-DOF pose correction, deep reinforcement learning for beam angle optimization, and clinical validation on a CyberKnife platform.
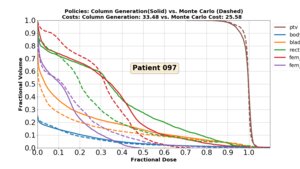

Abstract
We frame beam orientation optimization (BOO) in radiation therapy as a sequential decision problem and train a deep neural network policy using imitation learning from a column-generation solver. The learned policy selects coplanar and non-coplanar beam configurations that rival expert-optimized plans while running in real time.

Abstract
We present a minimax iterative dynamic game algorithm for robust nonlinear robot control under adversarial perturbations. The method frames the control problem as a two-player zero-sum game and computes feedback policies via saddle-point iterations on the Hamilton-Jacobi-Isaacs equation, achieving superior robustness on a 6-DOF arm tracking task compared to standard optimal control baselines.


Abstract
Soft-NeuroAdapt is a three-degree-of-freedom soft actuator system coupled with a neuro-adaptive controller that corrects patient head pose in real time for maskless frameless cancer radiotherapy. The neural adaptive law compensates for actuator and tissue nonlinearities, achieving sub-millimeter positioning accuracy without requiring a rigid fixation mask.

Abstract
We present a vision-based closed-loop control architecture for a pneumatic soft robot that positions a patient's head during maskless cancer radiotherapy. A model-free adaptive controller uses real-time pose feedback from a stereo camera to drive positioning error below the clinical tolerance of 1 mm.

Abstract
We describe the first real-time soft-robotic patient positioning system for maskless head-and-neck cancer radiotherapy, demonstrating a proof-of-concept platform that uses pneumatic actuators and image-based feedback to maintain sub-millimeter positioning accuracy during treatment fractions.
Technical Reports

Towards Real-Time Motion Compensation in Radio-Transparent Robotic Radiation Therapy
Technical Report

Abstract
We develop a deep reinforcement learning algorithm for zero-sum two-player games that is robust to function approximation errors and sparse rewards. The approach uses adversarial training and minimax Q-learning, achieving stronger worst-case guarantees than standard DRL baselines on robotic manipulation and locomotion tasks.

Abstract
We identify nonlinear dynamical systems using deep recurrent neural networks trained end-to-end on input-output data. Applied to soft-robot dynamics identification, the approach outperforms classical system identification methods and provides a differentiable model suitable for model-based control.
Presentations

Lagrangian Properties and Control of Soft Robots Modeled with Discrete Cosserat Rods.

Composite Fast-Slow Backstepping Design for Nonlinear Singularly Perturbed Newton-Euler Dynamics: Application to Soft Robots.

PcLast: Discovering Plannable Continuous Latent States.


A Real-Time Patient Head Motion Correction Mechanism for MRI-Linac Systems
Oral Presentation at Medical Physics 47 (6)(AAPM) E328-E328. Online only publication in the Medical Physics Journal, Annual Meeting of the American Association of Physicists in Medicine (AAPM)

A Real-Time Patient Head Motion Correction Mechanism for MRI-Linac Systems

A Motion-Planner for Robot Head Motion Correction in Stereotactic Radiosurgery

Towards Closed-Loop Control Head Motion Correction with Soft Actuators in MRI-LINAC Systems
Oral Presentation at Medical Physics (AAPM) 46 (6). Online only publication in the Medical Physics Journal, Annual Meeting of the American Association of Physicists in Medicine (AAPM)


A Reinforcement Learning Application of Guided Monte Carlo Tree Search Algorithm for Beam Orientation Selection in Radiation Therapy
Oral Presentation at Medical Physics (AAPM) 46 (6), E236-E236. Proceedings in the 60th Annual Meeting of the American Association of Physicists in Medicine (AAPM), San Antonio, TX.

An Approximate Policy Iteration Scheme for Beam Orientation Selection in Radiation Therapy
Oral Presentation at Medical Physics (AAPM) 46 (6), E386-E386. Online only publication in the Medical Physics Journal, Proceedings in the 60th Annual Meeting of the American Association of Physicists in Medicine (AAPM), San Antonio, TX.

Minimax Iterative Dynamic Game: Application to Nonlinear Robot Control Tasks

Automating Beam Orientation Optimization for IMRT Treatment Planning: A Deep Reinforcement Learning Approach
60th Annual Meeting of the American Association of Physicists in Medicine (AAPM), Nashville, TN

Minimax Iterative Dynamic Game: Application to Nonlinear Robot Control Tasks

Robustness Margins and Robust Guided Policy Search for Deep Reinforcement Learning
IROS 2017 Abstract Only Track
